Big Data Processing with Deep Learning - Spark vs TensorFlow
 Awantik Das
Awantik Das

More and more organizations are integrating big data pipeline with deep learning infrastructure. This is something, Spark & TensorFlow folks have in mind as well. Let’s have a quick glance about their journey so far.
Spark
-
Came as an alternative to old school Hadoop’s Map-Reduce.
-
It’s fast because of in-memory computing.
-
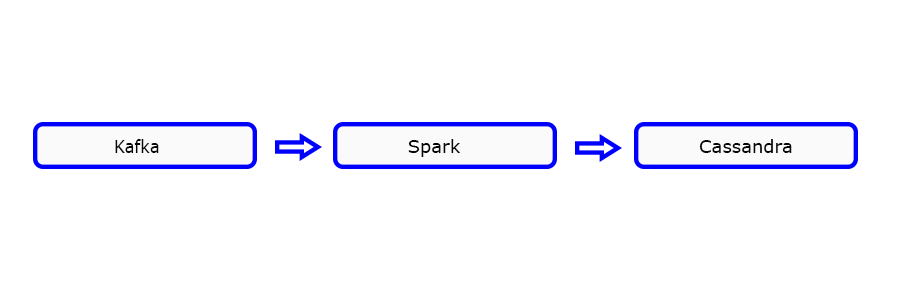
Super social in nature, could interact with all Big Data technologies like Kafka, HDFS, Cassandra & many more.
-
Easy to deal with, developer-friendly, do more by writing less.
-
You can scale using your commodity hardware.
-
Spark has many machine learning algorithms implemented.
-
For deep learning it allows porting TensorFlow on spark using open source libraries from various sources.
-
Building a data pipeline using Spark looks like -
TensorFlow
-
TensorFlow came from Google & very soon become the most trusted AI technology adopted, industry-wide for deep learning.
-
Fundamentally, TensorFlow is something more generic - ‘open-source scientific computing library’.
-
List of other TensorFlow libraries
-
Now, TensorFlow as grown into much beyond deep learning library. One of the functionalities TensorFlow provides is the
-
Ability to build big data pipeline is just one of many functionalities that TensorFlow provides.
-
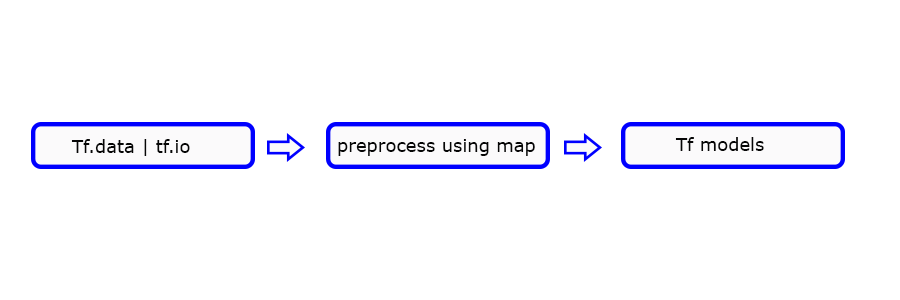
Tensorflow.io & tf.data allows you to read data from different sources.
-
Audio, image & text preprocessing infrastructure is now inbuilt with TensorFlow.
-
Building a data pipeline using TensorFlow looks like -
Conclusion
-
The journey of Spark & TensorFlow has been different. Spark started with big data ecosystem and then moved towards Machine learning whereas Tensorflow started as Machine learning library and now headed to provide full big data ecosystem.
-
Three things decide the winner in the increasing order of importance
-
Performance
-
Stability
-
Ease of use
-
Over a period of time, there will be one absolute winner for big data processing with deep learning stack. Only time will answer.
Keywords : Artificial Intelligence data-science spark Machine-Learning
Recommended Reading

Things you need to know to have a career in the Internet of Things (IoT)
Many people want to take up a career in the Internet of Things, but let me tell you this, it will be a stiff mountain to climb. But once you have reached the peak then there’s no stopping you. Here are some things you should know to have a career in the Int...

The Vital Role of Big Data to Fight Against Corona virus
With the number of cases of COVID-19 is increasing multifold, countries affected with coronavirus are making every considerable endeavor to use advanced technologies to trace and curb its outbreak. The World Health Organization (WHO) has also said that AI a...

Impact of Artificial Intelligence, Big Data and Technology on the Financial Sector: Disruption
The financial services sector was one of the first sectors to understand the wave of new technology which included Artificial Intelligence (AI) and the promise of the Big Data Revolution. Businesses in this sector, define themselves by their ability to make...
The Machine Learning Pipeline - Essential things to know before getting started with machine learning
Starting from development to deployment of machine learning, the journey of a product can be broken down to 7 important stages: Business Understanding, Data Wrangling, Visualization, Preprocessing, Model Training, Model Validation, Deployment

What are Big Data, Hadoop & Spark ? What is the relationship among them ?
Big Data is a problem statement & what it means is the size of data under process has grown to 100's of petabytes ( 1 PB = 1000TB ). Yahoo mail generates some 40-50 PB of data every day. Yahoo has to read that 40-50 PB of data & filter out spans. E-commerce...